![[PIC]](asm071.jpg) |
Dept. of Computer Engineering Prince of Songkla University Hat Yai, Songkhla, Thailand E-mail: ad@coe.psu.ac.th 15th March 2001 Last Updated: 21st November, 2001 |
![[PIC]](CoU01.jpg)
|
|
Dept. of Computer Engineering Prince of Songkla University Hat Yai, Songkhla, Thailand E-mail: ad@coe.psu.ac.th 15th March 2001 Last Updated: 21st November, 2001 |
|
![[PIC]](mad050.jpg)
ComicSearch searches for comic covers and information using:
Your machine must have a copy of Java 2 since ComicSearch is a Java application. Java can be obtained for free from http://java.sun.com/j2se/. Either download the Standard Development Kit (SDK) if you plan to write your own Java programs, or the Runtime Environment (JRE) which is sufficient for running ComicSearch.
The source, compiled code, support files, and documentation for ComicSearch only amount to a bit under 360K, so don't worry about disk space.
ComicSearch requires a network connection, so it can do its searching. ComicSearch can be used through a proxy/firewall (details below).
It displays its URLs by calling your machine's default browser, such as Netscape, Internet Explorer, or Opera (my current favourite).
ComicSearch has only been tested on Win 9* and 2000, but it should work on any platform that supports Java.
C> java ComicSearchIf you access the Web through a firewall, you will have to do a bit more than this. See below for details.
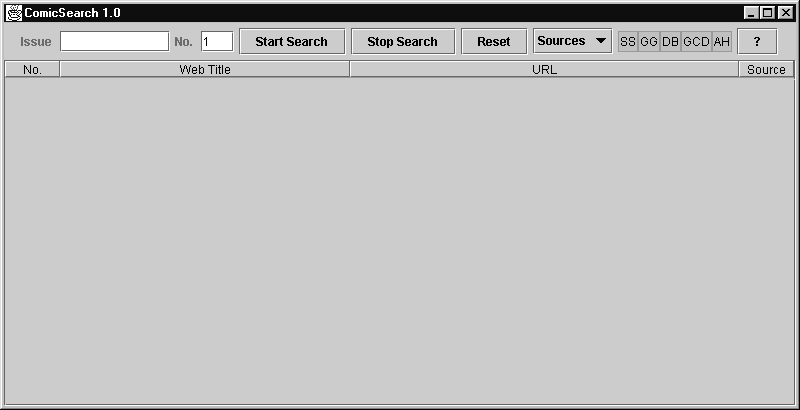 Also look occasionally at the DOS window since error messages
and less important information messages are printed there.
Also look occasionally at the DOS window since error messages
and less important information messages are printed there.
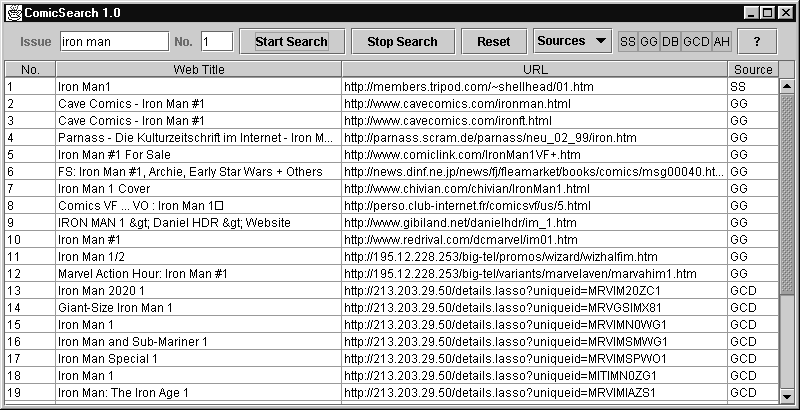
The 'run bar' at the top right of the GUI shows the status of the various searches. SS stands for Nick Simon's Marvel Silver Age search engine, GG for Google, DB for the local database, GCD for the Grand Comic Database search engine, and AH for the AuctionHawk search engine.
When searches are in progress, the squares will turn green. When the searches have finished, the boxes will revert to gray.
A user doesn't need to wait for the searches to complete, they can be asked to stop by the user presssing the "Stop Search" button. Note: the searches may continue for a short time after the button has been pressed.
The local database contains a large number of sites which ComicSearch will examine for comics. A list of these sources can be seen by clicking on the "Sources" combo box in the GUI:
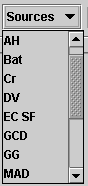
Clicking on a source ID (e.g. GCD) will display a dialog box giving details on the source's name and URL:
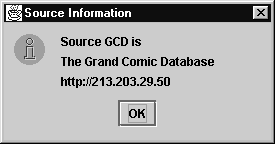
The source IDs are also used in the fourth column of the table, to identify where comic information comes from. If you click on a sourceID in the column then the URL of that site will be loaded into your browser.
ComicSearch can be supplied with proxy and authorization information to permit it to access Web sites through a firewall.
The information must be added to the file proxyInfo.txt, which is in the ComicSearch directory. The format of the file consists of three special lines:
proxyHost: [your proxy's address] proxyPort: [your proxy's port number] authID: [your login ID for authorization]
The authID line may not be necessary for some proxies. You need an authID line if you get a login/password dialog when you normally use the browser on your machine.
The file format allows blank lines, and lines beginning with // are treated as comments.
proxyInfo.txt is used if ComicSearch is called with the -proxy option:
C> java ComicSearch -proxy
If ComicSearch sees an authID line in the file then it will display a password dialog box for you to enter your authorization password. DO NOT TYPE YOUR PASSWORD INSIDE proxyInfo.txt.
If you have several proxy/authorization IDs, then you can put the details in several text files (e.g. proxyInfo.txt and p2.txt) and supply the filename as an argument to the -proxy option:
C> java ComicSearch -proxy p2.txt
An important part of ComicSearch is its database of sites to search for comic information. The database is just a text file (titlesDB.txt) in the ComicSearch directory, with a fairly simple format.
One of my hopes for ComicSearch is that the large army of Comic collectors out there will add their information to the database, so improving ComicSearch for everyone.
Contributing your details is simple:
Probably the best thing for you to do is to look through titlesDB.txt. The format is pretty obvious after a few examples.
A new site is identified by three source lines. e.g.:
sourceID: AD
sourceName: Andrew's Banana Collection
sourceURL: http://foobar.com/~ad/banana/
The source URL is normally the top page of the collection.
This information is used by the "Sources" combo box and the fourth column of the display table.
After the source details, information on each title is supplied using 4 lines. e.g.:
Title: The Mighty Banana
Issues: 2 4 56-67 1002
imageURL: http://foobar.com/ban***.htm
$
This describes my extensive collection of the well-known comic "The Mighty Banana". Issues can be single numbers or ranges. imageURL is the URL of the comic details (e.g. the cover scans). But notice that the URL contains *'s, which will be replaced by a issue number when ComicSearch displays the URL.
For example, if I search for issue 2 of "The Mighty Banana", then the image URL returned will be http://foobar.com/ban002.htm. The *'s are left-padded with 0's if the issue number is smaller than the *'s.
If I search for issue 1002, the returned URL will be http://foobar.com/ban1002.htm. Numbers which are bigger than the *'s are inserted without any padding.
This means that your cover scans will have to be labelled in this style (e.g. the URLs must contain the issue number). This seems a fairly standard thing, and is actually helpful when you're storing 100's of scans at your site.
A collection of issues with the same title, but different image URLs can be grouped without repeating the title:
Title: The Mighty Banana
Issues 2 4 56-67 1002
imageURL: http://foobar.com/ban***.htm
$
Issues: 1005-1222
imageURL: http://narfoo.com/ban***.html
$
Blank lines and lines beginning with // are ignored inside titlesDB.txt when it is read in.
Of course, we used the wonderful class library in Java 2.
The analysis of the search engine results was greatly helped by using regular expressions supported by the COM.stevesoft.pat package, shareware release 1.3.2. It can be obtained from http://javaregex.com
We used two Java Tips from the JavaWorld Web site (http://www.javaworld.com):
This ComicSearch Web page is: http://coe.psu.ac.th/~ad/ComicSearch/readme.html
Andrew Davison can be sent e-mail at: ad@coe.psu.ac.th